To meet the challenges of using model checking in the context of current trends in software development outlined in previous section, we have constructed an extensible and highly modular explicit-state model checking framework called Bogor . Using Bogor, we seek to enable more effective incorporation of domain knowledge into verification models and associated model checking algorithms and optimizations, by focusing on the following principles.
- Direct Support of Modern Language Features:
Bogor checks systems specified in a revised version of the Bandera Intermediate Representation (BIR). The previous version of BIR was designed to be an intermediate language used by Bandera for translating Java programs to the input languages of existing model checkers such as SPIN. Thus, this earlier version provided direct support for modeling Java features such as threads, Java locks (supporting wait/notify), and a bounded form of heap allocation. To facilitate the construction of translators to back-end model checkers like SPIN, BIR control-flow and actions are stated in a guarded command format which it quite close to the format used to specify systems in model checker input languages like Promela.
Our experience with Bandera and other tools such as JPF and dSPIN has led us to conclude that software model checking can be more effectively supported by a new infrastructure that has at its core an extensible model checker that is designed to support software directly rather than relying on translations to model checkers that do not provide direct support for modeling many of the language features found in modern software. As part of this transition to a new infrastructure, we have revised the definition of BIR to include a number of new features such as the BIR extension mechanism, generic types and polymorphic functions, type-safe function pointers, virtual function/method tables, and exceptions.
In contrast to the input languages used in almost all other model checkers (including SPIN, NuSMV, SLAM, BLAST ), BIR supports unbounded dynamic creation of both thread and heap objects with automatic reclamation by garbage collection. Moreover, BIR provides a state-of-the-art canonical heap representation that seems essential for effective checking of highly dynamic concurrent software systems. Such systems generate many heap instances that differ in the relative position of allocated objects but that are actually observationally equivalent (i.e., the heap instances can not be distinguished by any Java memory operations). Due to positional differences of object placement in heaps, conventional representations of heaps as, for example, arrays of memory cells would yield different states for these heaps. However, Bogor's canonical heap representation (based on work by Iosif on dSPIN) ensures that heaps that are observationally equivalent map to the same state. This dramatically reduces the number of states generated when checking highly dynamic systems.
- Extensible Modeling Language:
Figure 1.1. Declaration of set ADT and operations
extension Set for edu.ksu.cis.projects.bogor.module.set.SetModule { typedef type<'a>; expdef Set.type<'a> create<'a>('a ...); expdef 'a selectElement<'a>(Set.type<'a>); expdef boolean isEmpty<'a>(Set.type<'a>); actiondef add<'a>(Set.type<'a>, 'a); actiondef remove<'a>(Set.type<'a>, 'a); expdef boolean forAll<'a>('a -> boolean, Set.type<'a>); }BIR's extension facility allows modelers to add new types, expressions, and commands. Figure 1.1, “Declaration of set ADT and operations” presents a set extension declaration. An extension declaration consists of: (1) a signature declaration which specifies the new symbols and associated arities to be introduced into the name-spaces for types, expressions, and actions, and (2) the name of a Java package that implements the semantics of the extension. Note that the extension does not extend the BIR grammar, but only adds names to the set of names of built-in expressions, actions, etc. This means that the developer does not need to extend the parser or other syntactic support facilities. Rather, the developer traverses the extension structure and implements the extension semantics using well-defined APIs for BIR's existing abstract syntax trees and Bogor model checker components.
Extensions provide a convenient way to realize domain-specific abstractions of software components or layers, and to address the input language gap for modeling domain-specific software artifacts. Often times, there are component/layers of the software that have a significant amount of state that is irrelevant to the properties being checked. Rather than maintaining a complete implementation of a software component/layer using BIR's variables, the Java package implementing the extension can hold the state associated with the complex component/layer and only expose as much as is relevant at the BIR level. Since only the BIR variables are held in Bogor's state vector during model checking, this can dramatically reduce the costs of representing portions of a software system.
Hiding complex portions of the state in this manner is not novel. For example, when modeling communication protocols using SPIN, channel data types (chan) are often used to model message-passing channel in networks. This can be done because the specific implementation of the network channels is irrelevant with respect to the properties being checked. The properties are usually only concerned with the functional behavior of the channels, i.e., rendezvous, asynchronous, synchronous, and sending and receiving messages. Furthermore, properties are usually only concerned with a channel's abstract states, i.e., the specific channel implementation state, for example, the state of message retransmission protocols used to provide the channel service, does not need to be exposed in the model state. What is novel about BIR is that it does not a priori hard-code such abstraction mechanisms for a particular domain -- rather, BIR's extension facility provides an open-ended mechanism for adding any number of domain-specific abstractions. For example, BIR extensions are used to represent the functionality of the Real-Time CORBA Event Service in our work on checking CCM designs in the Cadena project.
- Open Modular Architecture:
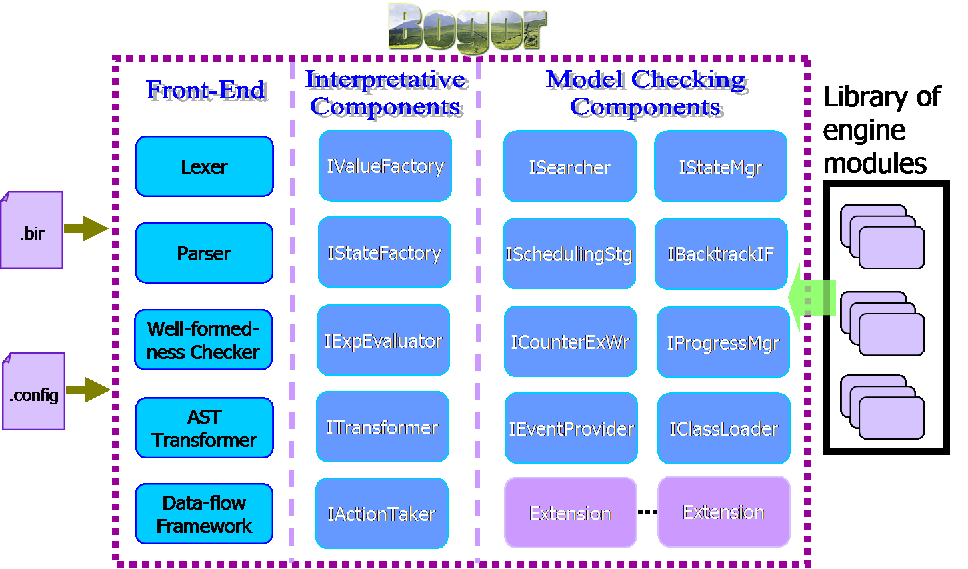
Figure 1.2, “Bogor Architecture” presents the Bogor architecture that is divided into three parts: (1) a front-end that parses and type checks a given model expressed in the BIR modeling language, and (2) interpretive components that implements the values the state transformations implied by BIR's semantics, and (3) model checking engine components that implement search and state storage strategies.
All model checking tools include functional aspects for state-space search, scheduling, and managing seen before states. However, in their implementations, these aspects are often tangled, and thus insertion of alternate strategies or other customizations is often quite difficult. One of the contributions of our work is not just to present a non-tangled implementation, but moreover to present core components using widely-used and well-documented design patternsthat hide irrelevant implementation details by encapsulation, that reduce dependences between components, and that build in strategies for parameterization, adaptation, and extension.
For example, the ISearcher (implemented using the Strategy pattern) defines the search method used. For example, if depth-first search is used, then at any given state, its children states will be explored first before exploring its sibling states. The IStateManager (implemented using the Facade pattern) for provides a interface for storing states and for determining whether or not a state has been visited before. The ISchedulingStrategist (Strategypattern) determines the scheduling strategy employed by the model checker. The most common strategy of model checkers is to generate all possible interleavings of thread executions. Other strategies include incorporation of support for priority based scheduling. In addition, when processing any inner-thread non-deterministic choice (e.g., associated with multiply-enabled transitions within the same thread), this module should be consulted to determine which transition to execute next. For example, in a full-state exploration mode, the scheduler should make sure that every branch of a non-deterministic choice should be explored. This module is also consulted to determine which transformations are enabled in a given state.
- Design for Encapsulation:
Bogor graphical user interface (GUI) is implemented as a plug-in for Eclipse -- a freely available open source and extensible universal tool platform from IBM. Figure 1.3, “Bogor Counter Example Display” presents Bogor counter example display inside Eclipse. Eclipse provides a rich set of infrastructure for, for example, creating integrated development environments (IDEs), graphical editors, etc., that is ideal for building a user interface (UI) for a model checking tool. Eclipse provides a plugin facility by which one can add more functionality. The plugin facility of Eclipse matches well with Bogor's module extension facility. Eclipse, like Bogor, is implemented in Java. Thus, it allows a tight integration of Bogor and its GUI context and extensions.
Our own experience of customizing Bogor with domain-specific modeling primitives and optimizations and encapsulating the resulting customized tool within larger environments has been quite positive.
We are developing the next generation of the Bandera tools in Eclipse. This new version of Bandera analyzing models generated from Java source code using Bogor's rich built-in support for modern language features. For these primitives, we have extended Bogor's default algorithms to support state-of-the-art model reduction/optimization techniques that we have developed by customizing for object-oriented software existing techniques such as collapse compression, heap symmetry, thread symmetry, and partial-order reductions.
In our work on the Cadena development environment (also built in Eclipse)for designing large-scale distributed real-time embedded systems built using the CORBA Component Model (CCM), we have extended Bogor's modeling language to include APIs associated with the CORBA component model and an underlying real-time CORBA event service. For checking avionics system designs in Cadena, we have customized Bogor's scheduling strategy to reflect the scheduling strategy of the real-time CORBA event channel, and created a customized parallel state-space exploration algorithm that takes advantage of properties of periodic processing in avionics systems. These customizations for Bandera and Cadena have resulted in space and time improvements of over three orders of magnitude compared to our earlier approach which created models for SPIN and dSPIN.
In other work, we have extended Bogor to support checking of specifications written in the Java Modeling Language (JML) and GUI frameworks. Researchers outside of our group have extended Bogor to support checking of programs using AspectJ.
- Pedagogical Materials:
The success and the expediency of the customization efforts described above were determined by several factors: (1) accessibility to domain knowledge, (2) intimate understanding of existing model checking algorithms, and (3) a model checking framework that allowed us to rapidly prototype ideas as concrete algorithms that we could experiment with. We believe that these factors influenced not only our specific experiences, but the experiences of others in applying Bogor as well. While issues in (1) should be addressed by the practitioners themselves, it is crucial for us to provide tutorial and reference material about Bogor's architecture and algorithms to enable others to successfully customize Bogor. Moreover, we believe Bogor itself is an excellent pedagogical vehicle for teaching foundations and applications of model checking because it allows students to see clean implementations of basic model checking algorithms and to easily enhance and extend these algorithms in course projects to include a variety of enhancements and optimizations.
Bogor comes with this user manual that includes BIR documentation (e.g., grammar, language description, abstract syntax tree implementation in Java, etc.) and Bogor extension tutorials that are directly accessible through the Eclipse help system as well as in PDF and HTML format. These materials refer to a well-documented repository of examples that illustrate how to construct various types of Bogor extensions.
To use Bogor as a pedagogical vehicle for teaching foundations and applications of model checking, we designed an extensive collection of freely available course materials for a one-semester course (see Software Model Checking: Theory and Practice website).
This course emphasizes a practical and project-oriented approach to learning the technical foundations of model checking and methodologies for applying model checking tools to realistic systems. Foundational topics covered include basic explicit-state reachability algorithms, temporal specification formalisms including LTL and CTL, partial order reductions, state-space representations (collapse compression, etc.), and alternate search strategies. In an approach similar to that used in compiler courses, these foundational and theoretical concepts are reinforced by having students implement key components of an explicit state model checker.
Students learn to apply Bogor to model and analyze simple concurrent systems that illustrate basic concepts of state-space exploration. Programming projects involve (re)implementing or modifying the core modules of Bogor's model checking engine, or implementing new modeling language primitives using Bogor's extensible modeling language. In addition to simply reinforcing the central concepts of model checking, the overall goal of these implementation exercises is to move students to the point where they can effectively develop model checking tools and associated methodologies for verification of real world systems by tailoring Bogor to different application domains.
Methodological aspects of model checking (and Bogor, in particular) are also emphasized. This includes repeatable strategies for capturing concurrent/distributed systems as effective verification models, applying abstraction and other state-space reducing model transformations, and using a pattern-based approach to constructing temporal specifications.
The course distribution for instructors includes a variety of pedagogical materials such as typeset lecture notes and guided exercises, PowerPoint lecture slides, streaming video for our lectures, source code for lecture examples, weekly quizzes and solutions, homeworks and solutions, exams and solutions. A separate distribution for students includes only the lecture slides and examples.


In summary, we believe that a number of trends in software development suggest the need for flexible and adaptable infrastructure to enable practitioners to more effectively develop model checking tools that are customized to particular domains and development processes. While there are many avenues that one might pursue, we believe that the Bogor framework provides a robust and well-reasoned foundation that researchers and practitioners can use to address important facets of automated reasoning for modern software systems.